Le document que vous commencez à lire fait partie de l’ensemble des supports d’apprentissage proposés sur le site http://www.bdpedia.fr. Il constitue, sous le titre de « Aspects systèmes », la seconde partie d’un cours complet consacré aux bases de données relationnelles.
La version en ligne du présent support est accessible à http://sys.bdpedia.fr,
la version imprimable (PDF) est disponible à http://sys.bdpedia.fr/files/cbd-sys.pdf,
la version pour liseuse / tablette est disponible à http://sys.bdpedia.fr/files/cbd-sys.epub (format EPUB).
Ce support a pour auteur Philippe Rigaux, Professeur au Cnam. Je suis également l’auteur de trois autres cours, aux contenus proches:
Un cours sur le modèle relationnel et SQL à http://sql.bdpedia.fr.
Un cours sur les bases de données documentaires et distribuées à http://b3d.bdpedia.fr.
Un cours sur les applications avec bases de données à http://orm.bdpedia.fr
Reportez-vous à http://www.bdpedia.fr pour plus d’explications.
Important
Ce cours est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International. Cf. http://creativecommons.org/licenses/by-nc-sa/4.0/.
1. Introduction¶
Les Systèmes de Gestion de Bases de Données (SGBD) sont des logiciels complexes qui offrent un ensemble complet et cohérent d’outil de gestion de données: un langage de manipulation et d’interrogation (SQL par exemple), un gestionnaire de stockage sur disque, un gestionnaire de concurrence d’accès, des interfaces de programmation et d’administration, etc.
Les systèmes présentés ici sont les SGBD Relationnels, simplement appelés systèmes relationnels. Il s’agit de la classe la plus répandue des SGBD, avec des représentants bien connus comme Oracle, MySQL, SQL Server, etc. Tous ces systèmes s’appuient sur un modèle de données normalisé, dit relationnel, caractérisé notamment par le langage SQL. Les systèmes non-relationnels, vaguement rassemblés sous le terme générique « NoSQL » reprennent une partie des techniques utilisées par les systèmes relationnels, mais en diffèrent par deux aspects essentiels: l’absence d’un langage structuré et normalisé d’interrogation (et donc des techniques d’optimisation qui l’accompagnent), avec en contrepartie un grande facilité de passage à l’échelle par distribution. Reportez-vous à http://b3d.bdpedia.fr.
Le présent support de cours propose d’aller ”sous le capot” des systèmes relationnels pour étudier comment ils fonctionnent et réussissent le tour de force de proposer des accès sécurisés à des centaines d’utilisateurs en parallèle, tout en obtenant des temps de réponses impressionnants même pour des bases très volumineuses. Le contenu correspond typiquement à un cours universitaire de deuxième cycle en informatique. Il couvre les connaissances indispensables à tout informaticien de niveau ingénieur amené à mettre en place des applications professionnelles s’appuyant sur une base de données (soit une classe d’application extrêmement courante).
Il semble difficile de comprendre le contenu du cours sans avoir au préalable étudié les concepts principaux du modèle relationnel, et notamment le langage SQL. Reportez-vous au support http://sql.bdpedia.fr si vous avez un doute.
Contenu et plan du cours¶
Le cours est constitué d’un ensemble de chapitres consacrés aux techniques implantées dans les systèmes relationnels, et plus préciséments
les méthodes de stockage qui exploitent les ressources physiques de la machine pour assurer la disponibilité et la sécurité des bases de données;
les structures de données, parfois sophistiquées, utilisées par obtenir de très bonnes performances même en présence de très gros volumes;
les algorithmes et protocoles que l’on trouve à différents niveaux pour garantir un comportement robuste et efficace du système: optimisation des requêtes, contrôle de concurrence, gestion des pannes.
Le cours comprend trois parties consacrées successivement au stockage et aux structures de données, au méthodes et algorithmes d’optimisation, et enfin aux transactions et à la reprise sur panne.
Apprendre avec ce cours¶
Le cours est découpé en chapitres, couvrant un sujet bien déterminé, et en sessions. J’essaie de structurer les sessions pour que les concepts principaux puissent être présentés dans une vidéo d’à peu près 20 minutes. J’estime que chaque session demande environ 2 heures de travail personnel (bien sûr, cela dépend également de vous). Pour assimiler une session vous pouvez combiner les ressources suivantes:
La lecture du support en ligne: celui que vous avez sous les yeux, également disponible en PDF ou EPUB.
Le suivi du cours consacré à la session, soit en vidéo, soit en présentiel.
La réponse au Quiz proposant des QCM sur les principales notions présentées dans la session. Le quiz permet de savoir si vous avez compris: si vous ne savez pas répondre à une question du Quiz, il faut relire le texte, écouter à nouveau la vidéo, approfondir.
La pratique avec les travaux pratiques en ligne proposés dans plusieurs chapitres.
Et enfin, la réalisation des exercices proposés en fin de chapitre.
Note
Au Cnam, ce cours est proposé dans un environnement de travail Moodle avec forum, corrections en lignes, interactions avec l’enseignant.
Tout cela constitue autant de manière d’aborder les concepts et techniques présentées. Lisez, écoutez, pratiquez, recommencez autant de fois que nécessaire jusqu’à ce que vous ayez la conviction de maîtriser l’esentiel du sujet abordé. Vous pouvez alors passer à la session suivante. La réalisation des exercices est essentielle pour vérifier que vous maîtrisez le contenu.
Les définitions
Pour vous aider à identifier l’essentiel, la partie rédigée du cours contient des définitions. Une définition n’est pas nécessairement difficile, ou compliquée, mais elle est toujours importante. Elle identifie un concept à connaître, et vise à lever toute ambiguité sur l’interprétation de ce concept (c’est comme ça et pas autrement, « par définition »). Apprenez par cœur les définitions, et surtout comprenez-les.
La suite de ce chapitre comprend une unique session avec tout son matériel (vidéos, exercices), consacrée au positionnement du cours.
S1: rappels¶
Supports complémentaires:
Nous commençons par un court rappel des notions de base que vous devez maîtriser avant d’aborder la suite de ce cours. Tout ce qui suit est détaillé dans le support sur les modèles que vous trouverez sur le site http://sql.bdpedia.fr. Reportez-vous à ce texte si vous avez des doutes sur vos acquis.
Bases de données et SGBD¶
Commençons par une vision d’ensemble des composants constituant un système relationnel et ses applications, vision illustrée par la Fig. 1.1. On distingue trois niveaux, soit, de droite à gauche, le niveau physique, le niveau logique et enfin le niveau applicatif. Le niveau physique est celui qui nous intéresse essentiellement dans ce cours; le niveau logique est supposé connu; le niveau applicatif ne nous concerne pas ou de manière très indirecte.
Le niveau physique comprend la base de données proprement dite, qui n’est rien d’autre qu’un ensemble de fichiers stockés sur un support persistant (un disque magnétique généralement). Ces fichiers contiennent des données dites structurées, par opposition à des systèmes stockant des documents sans forme prédéfinie (cas par exemple d’un moteur de recherche). Dans le cas des systèmes relationnels, les fichiers de la base contiennent
soit la représentation binaire des tables relationnelles; chaque table est constituée d’un ensemble d”enregistrements, un par ligne;
soit des index, structures de données permettant d’accélerer les opérations sur les données, et notamment les recherches.
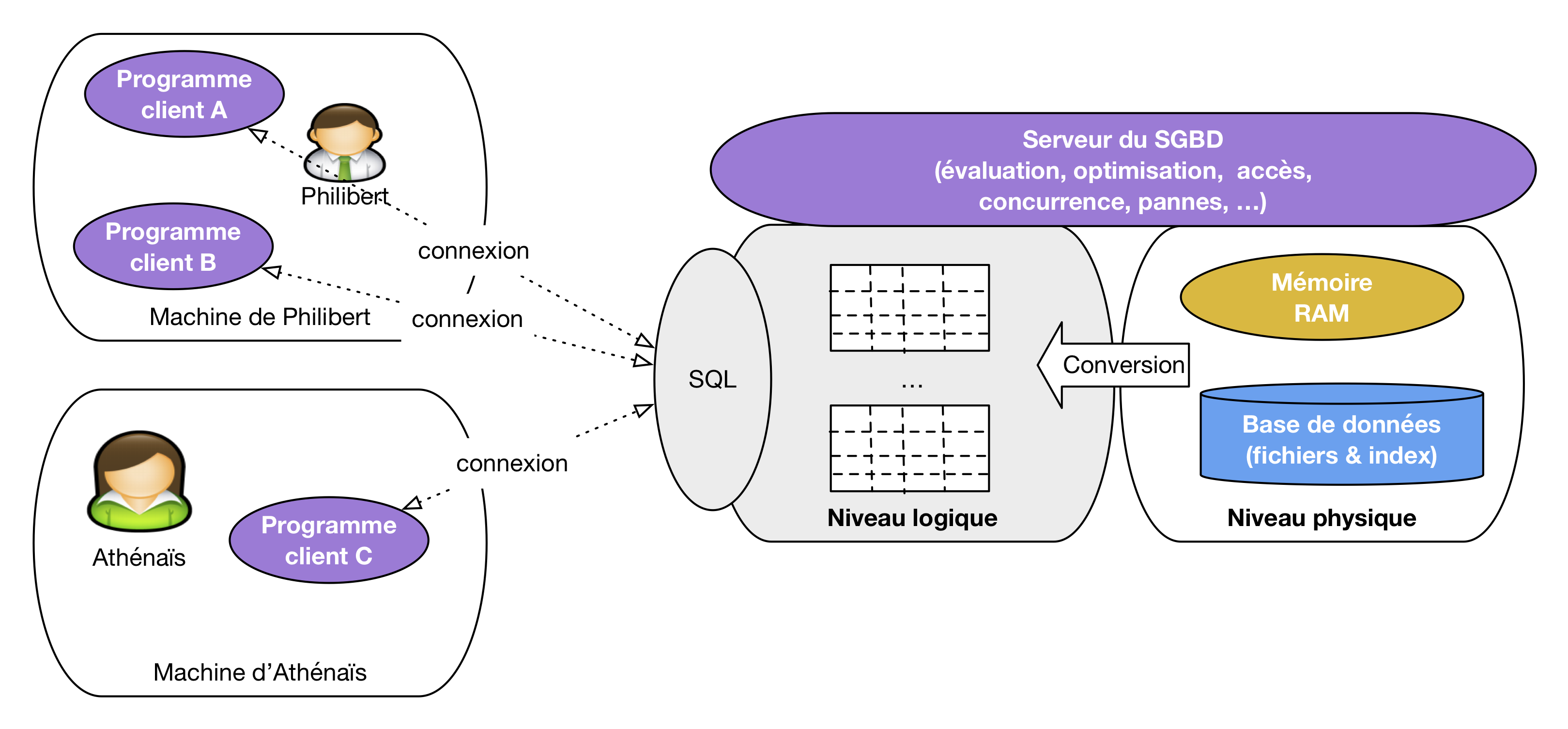
Fig. 1.1 Les composants d’un système relationnel¶
La persistance du support de stockage garantit la préservation de la base de données indépendamment des applications qui y accèdent. Une base de données continue à exister même quand la machine qui l’héberge est arrêtée, et tout est fait pour qu’elle puisse se conserver à long terme, par des procédures avancées de protection et de gestion des pannes. En contrepartie, les supports persistants étant beaucoup moins performants que les mémoires RAM, des stratégies sophistiquées d’accès sont nécessaires pour obtenir des bonnes performances.
Une base de données n’est jamais accessible directement pas une application car les fonctionnalitées évoquées ci-dessus (sécurité, performances) ne pourraient pas être assurées. Un système logiciel, le SGBD (système de gestion de bases de données) est chargé de prendre en charge tous les accès à la base. Le SGBD assure notamment
la gestion des ressources physiques: lecture et écriture dans les fichiers, maintenance des index, transferts entre mémoire secondaire (le disque) et mémoire RAM;
l’exécution efficace des opérations requises par les applications: lectures et mises à jour;
la gestion ordonnée des accès concurrents;
la sécurisation des données et notamment la gestion des pannes.
Par ailleurs, le SGBD présente aux applications les données selon un modèle qui fait abstraction de tous les détails techniques de la représentation physique. Dans les SGBD relationnels, ce modèle comprend des tables constituées de lignes.
Le niveau logique est celui de la présentation des données selon ce modèle. La distinction entre niveau logique et niveau physique offre d’immenses avantages qui expliquent en grande partie le succès des systèmes relationnels et la très grande simplification qu’ils ont apporté à la gestion de données informatiques.
le niveau logique offre une très grande simplication par rapport à la complexité du codage physique; cette simplification évite à tous ceux aui accèdent à une base de se confronter à des problèmes d’ouverture de fichiers, de codage/décodage de données binaires, et d’algorithmes de parcours complexes;
le niveau logique permet la définition de langages d’interrogation et de manipulation de données simples et intuitifs;
le niveau logique est indépendant du niveau physique: il est possible de réorganiser ce dernier de fond en comble sans que cela affecte aucunement les applications; on peut par exemple changer la base de machine, de support, la réorganiser entièrement, de manière complètement transparente.
L’indépendance logique / physique est l’atout maître des systèmes relationnels. Une conséquence pratique est qu’il est possible de distinguer deux rôles distincts dans l’utilisation d’un SGBD. Les concepteurs / développeurs ne voient que le niveau logique et les langages associés (SQL principalement). Il peuvent se concentrer sur la qualité fonctionnelle et applicative et n’ont pas à se soucier d’aspects non-fonctionnels comme les performances, la sécurité, la fiabilité ou les accès concurrents aux ressources. Les administrateurs sont, eux, concernés par le niveau physique et le réglage du système pour obtenir le comportement le plus satisfaisant possible.
C’est à ce second aspect qu’est consacré le support qui suit. Tout ce qui relève du niveau physique y est détaillé et expliqué. Les caractéristiques du modèle relationnel sont, elles, supposées connues et brièvement rappelées ci-dessous.
Le modèle relationnel¶
Les structures du niveau logique définissent une modélisation des données: on peut envisager par exemple des structures de graphe, d’arbre, de listes, etc. Le modèle relationnel se caractérise par une modélisation basée sur une seule structure, la table. Cela apporte au modèle une grande simplicité puisque toutes les données ont la même forme et obéissent aux même contraintes.
Pour rappeler les caractéritiques essentielles du modèle relationnel, nous allons nous appuyer sur un des exemples que nous allons traiter dans ce support de cours, celui d’une base stockant des informations sur des films, leurs acteurs et réalisateurs. Une telle base comprend plusieurs tables. Voici un extrait de celle des artistes.
id |
nom |
prénom |
année |
|---|---|---|---|
130 |
Eastwood |
Clint |
1930 |
131 |
Hackman |
Gene |
1930 |
132 |
Scott |
Tony |
1930 |
133 |
Smith |
Will |
1968 |
Une table relationnelle est un ensemble de lignes, et chaque ligne est elle-même constituée d’une liste de valeurs. Toutes les lignes ont la même structure, et donc le même nombre de valeurs. Une ligne représente une « entité » (ici, chaque ligne représente un artiste) et chaque entité est décrite par un ensemble fixe d’attributs (le nom, le prénom). Les valeurs de chaque ligne sont donc les valeurs de ces attributs caractéristiques de l’entité représentée. La régularité de la structure permet de représenter toutes les valeurs d’un même attribut dans une colonne, et de leur attribuer un type fixe (une chaîne de caractères pour le nom, un entier pour l’année).
Un peu de vocabulaire: table et ligne sont des termes informels pour parler du contenu d’une base relationnelle. Ils sont assez peu précis car ils ne spécifient ni le niveau de représentation auquel on se place, ni la structure particulière de leur contenu. En contexte, on peut s’en satisfaire, mais pour lever quelques ambiguités on adoptera dans ce support de cours la terminologie suivante
au niveau logique on préfèrera parler de relation pour désigner les tables et surtout de nuplet pour désigner les lignes; un nuplet est une séquence de valeurs typées, correspondant chacune à un attribut précis;
au niveau physique on parlera d”enregistrement (record) pour désigner le codage binaire d’un nuplet, et de collection pour désigner un ensemble d’enregistrements.
Dans chaque table relationnelle on trouve un attribut particulier, la clé primaire. La valeur de la clé primaire permet d’identifier un unique nuplet dans la table. Elle permet donc également de référencer ce nuplet depuis une autre table. Souvent, la clé primaire est un simple numéro d’identification.
Les attributs, leur type, la clé primaire, sont des contraintes qui s’appliquent à chaque nuplet. Ces contraintes sont décrites dans un schéma, déclaré au moment de la création de la table. Voici la commande de création de la table Artiste:
create table Artiste (idArtiste INTEGER NOT NULL,
nom VARCHAR (30) NOT NULL,
prénom VARCHAR (30) NOT NULL,
annéeNaissance INTEGER,
PRIMARY KEY (idArtiste));
On pourra représenter ce schéma par le résumé suivant, dans lequel on met en gras l’information essentielle, la clé primaire.
Artiste (idArtiste, nom, prénom, annéeNaissance)
Voici une seconde table, celle des films.
id |
titre |
année |
genre |
idRéalisateur |
codePays |
|---|---|---|---|---|---|
20 |
Impitoyable |
1992 |
Western |
130 |
USA |
21 |
Ennemi d’état |
1998 |
Action |
132 |
USA |
On retrouve les mêmes caractéristiques que pour les artistes: chaque film est décrit par des valeurs d’attributs, et identifié par une clé primaire. On trouve également dans cette table une clé étrangère: l’attribut idRéalisateur prend pour valeur l’identifiant d’un artiste. Cet identifiant est la valeur d’une clé primaire dans la table Artiste. La clé étrangère est donc un référencement, dans un nuplet (ici un film) d’un autre nuplet. Ce mécanisme permet de savoir que, par exemple, le réalisateur du film Impitoyable est Clint Eastwood. La clé primaire de ce dernier (130) est également clé étrangère dans la table Film.
Il est important de noter que le référencement n’est pas de nature « physique ». Il n’y a pas de « pointeur » qui lie les deux nuplets. C’est uniquement par calcul, au moment de l’exécution des requêtes, que l’on va comparer les valeurs respectives des clés étrangère et primaire et effectuer le rapprochement. Ce principe du calcul à la place d’un codage « en dur » est conforme à celui de l’indépendance logique/physique évoqué ci-dessus, et a un fort impact sur les algorithmes d’évaluation de requêtes.
Les clés étrangères sont des contraintes, et comme telles décrites dans le schéma comme le montre la commande de création de la table Film.
create table Film (idFilm integer NOT NULL,
titre varchar (80) NOT NULL,
année integer NOT NULL,
genre varchar (20) NOT NULL,
idRéalisateur integer,
codePays varchar (4),
primary key (idFilm),
foreign key (idRéalisateur) references Artiste(idArtiste),
foreign key (codePays) references Pays(code));
Vous devriez maîtriser sur la modélisation relationnelle pour aborder l’évaluation et l’exécution de requêtes. Voici, en résumé, le schéma de notre base des films.
Film (idFilm, titre, année, genre, résumé, idRéalisateur, codePays)
Pays (code, nom, langue)
Artiste (idArtiste, nom, prénom, annéeNaissance)
Rôle (idFilm, idActeur, nomRôle)
Internaute (email, nom, prénom, région)
Notation (email, idFilm, note)
Et pour compléter l’illustration des liens clé primaire / clé étrangère, voici un extrait de la table des rôles qui consiste ensentiellement en identifiants établissant des liens avec les deux tables précédentes. À vous de les décrypter pour comprendre comment toute l’information est représentée. Que peut-on dire de l’artiste 130 par exemple? Peut-on savoir dans quels films joue Gene Hackman? Qui a mis en scène Impitoyable?
idFilm |
idArtiste |
nomRôle |
|---|---|---|
20 |
130 |
William Munny |
20 |
131 |
Little Bill |
21 |
131 |
Bril |
21 |
133 |
Robert Dean |
Cette base est disponible en ligne à http://deptfod.cnam.fr/bd/tp.
Les langages¶
Un modèle, ce n’est pas seulement une ou plusieurs structures pour représenter l’information indépendamment de son format de stockage, c’est aussi un ou plusieurs langages pour interroger et, plus généralement, interagir avec les données (insérer, modifier, détruire, déplacer, protéger, etc.). Le langage permet de construire les commandes transmises au serveur.
Un langage relationnel sert à construire des expressions (les « requêtes ») qui s’appuient sur une base de données en entrée et fournissent une table en sortie. Deux langages d’interrogation, à la fois différents, complémentaires et équivalents ont été définis pour le modèle relationnel:
Un langage déclaratif, basé sur la logique mathématique.
Un langage procédural, et plus précisément algébrique, basé sur la théorie des ensembles.
Un langage est déclaratif quand il permet de spécifier le résultat que l’on veut obtenir, sans se soucier des opérations nécessaires pour obtenir ce résultat. Un langage algébrique, au contraire, consiste en un ensemble d’opérations permettant de transformer une ou plusieurs tables en entrée en une table - le résultat - en sortie.
Ces deux approches sont très différentes. Elles sont cependant parfaitement complémentaires. l’approche déclarative permet de se concentrer sur le raisonnement, l’expression de requêtes, et fournit une définition rigoureuse de leur signification. L’approche algébrique nous donne une boîte à outil pour calculer les résultats.
Le langage déclaratif: SQL¶
Le langage SQL, assemblant les deux approches est une syntaxe pratique pour le langage relationnel déclaratif (lequel est une variante de la logique des prédicats). Il est utilisé depuis les années 1970 dans tous les systèmes relationnels, et il paraît tellement naturel et intuitif que même des systèmes construits sur une approche non relationnelle tendent à reprendre ses constructions.
SQL exprime des requêtes comme des formules que doivent satisfaire les nuplets du résultat. Voici deux exemples:
select titre
from Film
where année = 2016
On note qu’il n’y a aucune référence à la méthode qui permet de calculer le résultat. Comme nous le verrons, il peut en exister plusieurs en fonction de l’organisation de la base, et c’est le système qui choisit la meilleure. C’est une illustration du principe d’indépendance logique / physique.
Le second exemple est une jointure:
select titre, prénom, nom
from Film as f, Artiste as a
where f.idRéalisateur = a.idArtiste
and année = 2016
On assemble des nuplets partageant une propriété commune, ici l’identifiant de l’artiste, représenté comme clé primaire dans la table Artiste et comme clé étrangère dans la table Film. Ici encore, aucune procédure de calcul n’est indiquée, et ici encore le système a plusieurs choix et effectuera celui qui lui semble le meilleur.
Le langage procédural: l’algèbre¶
Comment le SGBD peut-il inférer une procédure de calcul à partir d’une requête SQL? Par quelle démarche peut-il déterminer quel algorithme appliquer pour une requête SQL donnée? La réponse est dans un langage intermédiaire, l’algèbre relationnelle. L’algèbre est un ensemble d’opérateurs donc chacun prend en entrée une ou deux tables et produit en sortie un table. Ces opérateurs sont :
La sélection, dénotée \(\sigma\)
La projection, dénotée \(\pi\)
Le renommage, dénoté \(\rho\)
Le produit cartésien, dénoté \(\times\)
L’union, \(\cup\)
La différence, \(-\)
En les composant, on construit des requêtes qui s’interprètent comme des séquences d’opérations à appliquer à la base. Il ne reste plus alors au système qu’à choisir le bon algorithme pour chaque opérateur, et la méthode d’évaluation (on parle de plan d’exécution) de la requête en découle.
L’algèbre a un pouvoir d’expression identique à celui du langage déclaratif, et toute requête SQL peut donc se transcrire en une expression algébrique. Voici l’expression correspondant à la première requête SQL ci-dessus.
On compose une sélection (\(\sigma\)) pour trouver les films parus en 2016, suivi d’une projection (\(\pi\)) pour ne conserver que le titre.
La jointure s’exprime en algèbre ainsi:
Il reste à choisir l’algorithme pour la sélection (\(\sigma\)) et pour la jointure (\(\Join\)). Ce choix est dicté par des objectifs de performance, et constitue donc la base de processus d’optimisation de requête, qu’il est important de comprendre et auquel nous consacrons une partie sigificative de ce support.
Voici, en très résumé, ce que vous êtes censés connaître au moment d’aborder la suite. Les notions de niveaux logique et physique, les principes de conception des schémas relationnels, SQL et l’algèbre sont les fondements pour aborder les aspects systèmes des bases de données.
Vous pouvez vous tester avec le quiz qui suit avant d’entrer dans le cœur du sujet.
Quiz¶



Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table Of Contents
- 1. Introduction
- 2. Dispositifs de stockage
- 3. Structures d’index: l’arbre B
- 4. Structures d’index: le hachage
- 5. Moteurs de stockage
- 6. Opérateurs et algorithmes
- 7. Evaluation et optimisation
- 8. Travaux pratiques: optimisation
- 9. Transactions
- 10. Contrôle de concurrence
- 11. Reprise sur panne
- 12. Annales des examens
Recherche
Saisissez un ou plusieurs mots-clés.